Building Phone Agents for Healthcare
At Silna, we built an internal phone agent platform to automate outbound calls on behalf of our customers. This covers two primary workflows: calling insurance companies to verify patient benefits, and checking the status of submitted prior authorizations.
Why did we need this?
Part of Silna's offering is performing benefits checks and prior authorizations on behalf of healthcare providers. Both workflows occasionally require a phone call to an insurance company when no portal or API is available. For benefits checks, this means calling to retrieve a patient's plan details directly. For some specialties like ABA therapy, this is usually the only way to get accurate plan details. For prior authorizations, calling is typically the fastest way to find out whether a submitted auth has been approved or denied, so we do it routinely as a status check.
Human Calls
Before we could automate anything, we needed data. Specifically, recordings and transcripts of real insurance calls to understand what we were actually dealing with: phone trees, hold flows, the exact phrasing IVR systems use, how agents respond to different inputs. The problem is that healthcare call data is protected under HIPAA, so we couldn't purchase an existing dataset. We had to generate it ourselves.
We built a Voice over IP (VoIP) client directly into our application so our operations specialists could make and receive calls from their browsers without leaving our platform. We chose Twilio for call management because it gave us programmable control over the full call lifecycle. Through webhooks, we could capture recordings, pull transcripts, and store everything in a structured way as our specialists worked. Over time, this gave us a reliable corpus of real insurance call data to build from.
Beginning Automated Calls
Now that we had an up and running mechanism for our team to call within Silna, we were ready to start building the infrastructure for our automated phone agents.
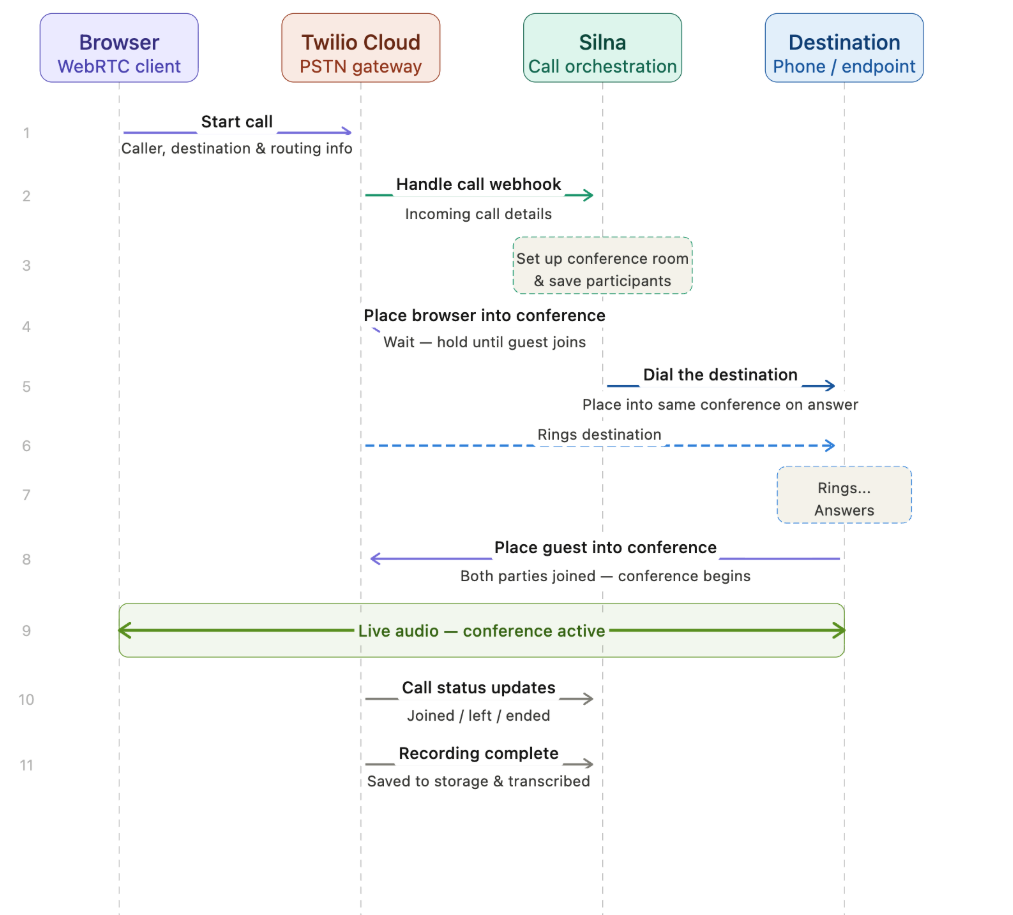
One major difference between the infrastructure we needed for human based calls and agent calls is that agent calls would need to be initiated from our core application while VoIP calls were connecting to Twilio straight from the browser.
The core challenge was Twilio's call initiation model. When you are ready to kick off a phone call your application must send an HTTP request to Twilio containing an endpoint for them to open a websocket connection with you. This means we would have to accept websocket connections from Twilio.
We wanted to keep websocket connections for agentic phone calls off our public-facing API, and we also wanted the agent orchestration to run on our asynchronous task workers instead of the workers serving our API.
To do this, we created Fabric. Fabric is a websocket proxy/pairing service. It is responsible for accepting websocket connection requests from both Twilio (or any external phone call provider) and Silna then matching up the correct connections with each other.
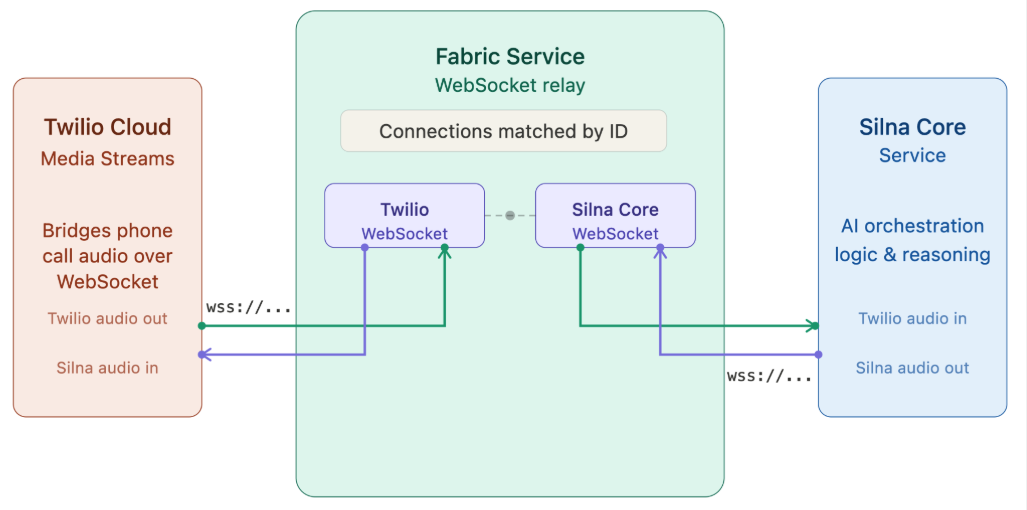
When an agentic call is initiated, we send an HTTP request to Twilio, and open a websocket connection with Fabric. Fabric then waits for Twilio to open the corresponding websocket connection with it so it can pipe audio back and forth between Twilio and Silna.
Problems With Third Party Phone Providers
With Fabric in place, we launched our first automated agent. We started with the simplest possible calls to automate: those requiring only IVR/DTMF navigation, punching in numbers in response to prompts like "Press 1 for benefits" or "Please enter the member ID."
V0 — Deepgram. We used Deepgram's agent framework for this. It handled DTMF tool calls reliably, but as soon as we moved beyond tone navigation into actual voice conversation, latency became a dealbreaker. Insurance company IVR systems have short timeout windows, and Deepgram's response times consistently caused them to time out and hang up.
V1 — Voice-to-Voice. We explored models that take in audio directly and produce audio as output, skipping the text layer entirely. The problem was reliability. Audio tokens encode tone, prosody, background noise, and semantic content all at once, and the models tended to optimize for what sounds natural over what is accurate. They struggled with following checklists and reading back sequences of numbers. On a sensitive insurance call, that kind of mistake can delay care for a patient. The other problem was guardrails. Without an intermediate text layer, we had no way to inspect or validate what the model was about to say before it said it.
V2 — ElevenLabs. We switched to ElevenLabs' agent framework, which was a significant step up in voice quality and responsiveness. But we quickly hit a different wall: HIPAA compliance. Because we operate under HIPAA, we require zero data retention (ZDR) agreements with our vendors. ElevenLabs supports ZDR, but with major trade offs; we had no access to call logs or transcripts, which made debugging tool-calling failures nearly impossible. After several weeks of debugging in the dark with no visibility into failures, it became clear that the constraints of third-party agent frameworks around observability, compliance, and model access were fundamentally at odds with what we needed to build. We decided to build our own.
Silna Voice Agent
Chained Silna Voice Agent
A phone call feels simple: someone speaks, the agent replies. In practice, every turn is a real-time coordination problem across transcription, reasoning, and voice generation, with sub-second budgets at each stage.
The Silna Phone Agent uses a chained voice architecture. Instead of sending speech directly into a speech-to-speech model, we break each turn into explicit stages:
- The caller's audio is transcribed by a speech-to-text (STT) system.
- The transcript is processed through our application and data pipeline.
- The large language model (LLM) decides what the agent should say next.
- The response is normalized, checked, and passed into a text-to-speech (TTS) system.
- The generated audio is streamed back to the caller.
Speech-to-speech models are harder to inspect, and on a healthcare call, an audit trail isn't optional. Chaining lets us see exactly what the caller said, what the model understood, what data we pulled, and what we said back. It also lets us add guardrails where they belong: validating structured data before it reaches the model, constraining what the model is allowed to say, and normalizing text before speech generation. Each layer can be debugged, measured, and improved on its own.
Audio Pipeline
So the question becomes: how do you wire them together without one slow step blocking everything else?
Our answer was to use queues.
Each step in the pipeline produces an output, puts it onto a queue, and moves on. The speech synthesizer does not know or care whether the "brain" has finished processing the entire response. It just pulls text from its queue, turns it into audio, and keeps going. The audio sender does the same thing with generated audio chunks.
That sounds simple, but queues ended up becoming one of the most important primitives in our system.
They let us decouple each part of the pipeline, but they also give us a control surface. When the caller interrupts the agent while it is talking, we can clear the queues and discard anything the agent was about to say but had not said yet. Without that, the agent might keep talking from an old response even after the caller has already moved the conversation somewhere else.
We also use sentinel values in the queue to mark sentence boundaries. This lets us track which sentences were actually heard by the caller and which ones were still in flight. That distinction matters a lot. In a chat app, once a message is displayed, you can assume the user saw it. In a phone call, generated audio might exist in our system but never actually reach the caller.
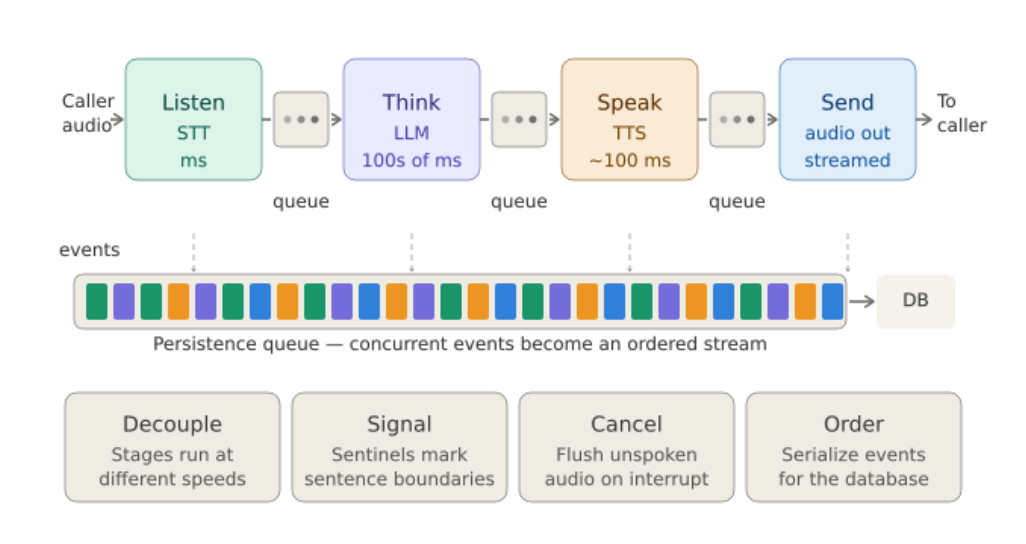
Finally, we funnel events from all of these concurrent tasks into a persistence queue. Instead of letting every task write to the database whenever it wants, we turn the whole conversation into an ordered stream of records. That gives us a clean timeline of what happened: what the user said, what the agent generated, what audio was sent, what was interrupted, and what was actually heard.
Twilio
The audio starts with Twilio.
Twilio streams the call audio to our servers over a WebSocket as JSON events. Each event carries a base64-encoded payload of audio, arriving in small chunks of compressed phone audio while the caller is speaking.
Listener - Speech-to-Text
The raw caller audio goes through our listener, which is responsible for STT.
The STT model listens to the caller and transcribes their speech into text. But once this is happening live, over the phone, harder questions come up:
- How do we know when the caller has stopped speaking?
- What do we do when the caller interrupts while the agent is speaking or still processing?
- How do we make sure domain-specific words like insurance carriers, clinic names, medications, and procedure names are transcribed correctly?
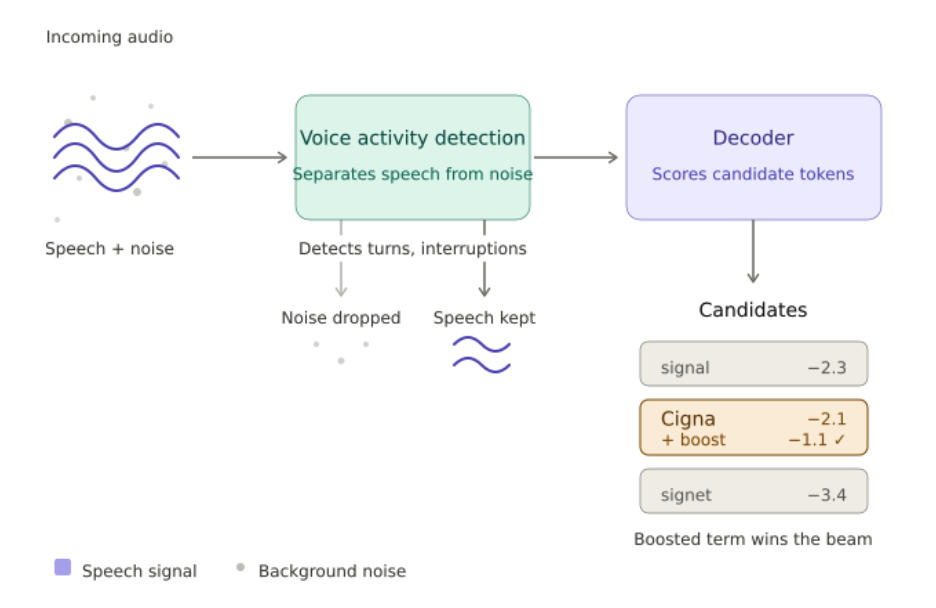
We use Deepgram for the STT layer. It gives us a strong starting point: fast transcription, turn detection, and better handling of conversational speech. But a good STT model isn't a good listener on its own. The listener has to decide when the caller is done, when a transcript is stable enough to act on, and when to hold off entirely.
Keyword boosting is one place where domain matters. We tell the STT model to prioritize specific terms during decoding: insurance carrier names, CPT codes, clinic names. If the caller says "Cigna," we don't want the transcript to say "signal." That sounds minor, but in a healthcare workflow, misunderstanding the carrier can send the rest of the conversation down the wrong path: a prior auth filed to the wrong payer, rework for the clinic, delays for the patient.
Endpointing, figuring out when the caller is actually done talking, is one of the more delicate parts of the pipeline. Wait too long after they stop, and the agent feels slow. Respond too early, and we cut them off. Callers don't always pause neatly between sentences; someone looking up their member ID might trail off with "hold on, it's, um..." and a trigger-happy system will start talking over them. The goal is responsive without impatience.
Interruption handling is where a lot of the real-time complexity shows up. When the caller starts speaking while the agent is talking, the listener doesn't just transcribe the new speech. It kicks off a cascade: we clear queued audio, cancel the in-progress LLM response, and tell Twilio to flush its buffer.
But stopping isn't enough. We also need to know exactly what the caller heard before they interrupted. We track this through a mark confirmation system: as the agent speaks, we place markers at sentence boundaries in the audio stream, and Twilio tells us when each marker has actually reached the caller. When an interruption happens, we can split the response into what was delivered and what was still in flight. The conversation history stays accurate, which means the agent doesn't repeat itself or lose context.
There's an even trickier case: the caller starts speaking before the agent's audio has even begun playing, while the LLM is still generating. We detect this and throw out the in-progress generation entirely, folding the caller's new input into a fresh response instead of playing something stale.
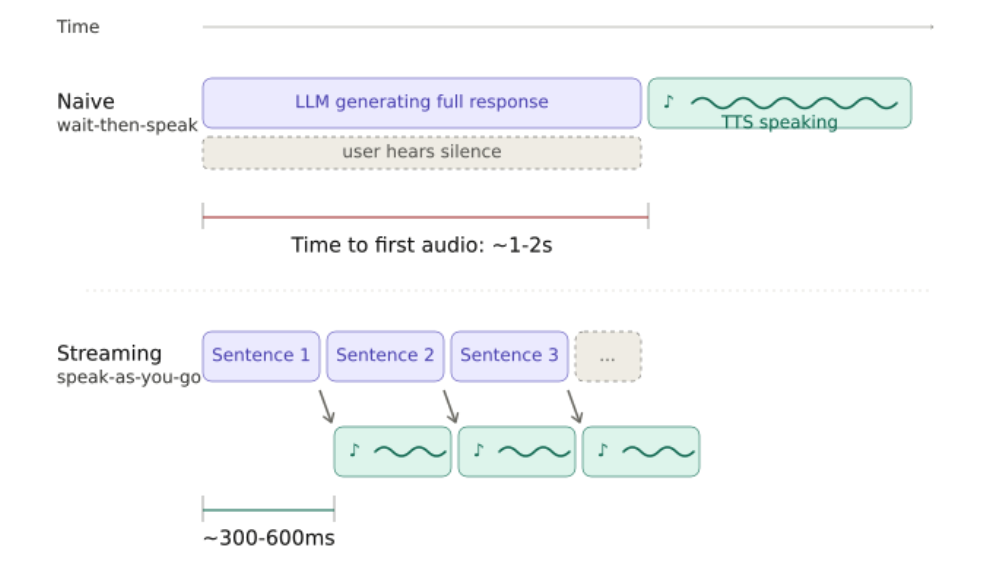
The Brain - LLM
The hard part is latency. Even with a fast model, a full response can take a second or two to generate. We solve this by not waiting for the full response. As the LLM streams tokens, we extract complete sentences from the output and send each one to the speech synthesizer as soon as it is ready. The caller starts hearing the response while the brain is still finishing the rest of the thought. Sentences are the right unit here: individual tokens would make the audio choppy and hard to control, and waiting for the whole response is too slow.
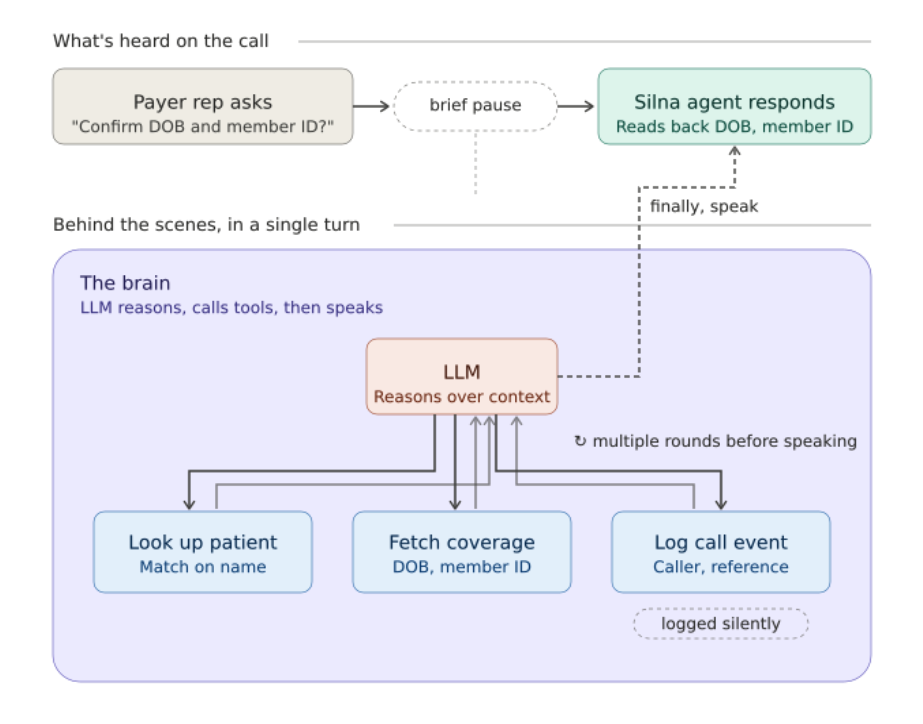
But generating speech is only part of what the brain does during a call. The more interesting part is that the brain can act.
Within a single conversational turn, the LLM can call tools: look up a patient's insurance benefits, query internal databases, or pull up provider details. When it does, we execute the tool, feed the result back to the LLM, and let it generate a new response that incorporates what it found. This can happen over multiple rounds within a single turn.
Not every tool call needs to be spoken about. Some tools are configured to run silently. For example, the agent might need to press buttons on a phone menu to navigate an insurance company's system. It does this by sending DTMF tones in the background, without announcing each keypress to the caller. A real conversation has things happening beneath the surface, and the agent should not announce all of them.
The model we use matters a lot. A larger model may reason better, but if it takes too long to produce the first sentence, the caller is stuck waiting. A smaller, faster model may respond quickly, but can require more prompting and validation to stay accurate. We are not just asking which model gives the best answer. We are asking which model can produce a reliable answer quickly enough to feel like a real conversation.
Speech Synthesizer - Text-to-Speech (TTS)
By the time text reaches the synthesizer, sentences are streaming in one at a time from the LLM. The challenge is starting audio fast enough that the caller doesn't notice the gap. More expressive TTS models produce more natural speech but take longer to start; lower-latency models speak faster but give us less control over tone. We're tuning that tradeoff constantly.
A subtler problem is what happens between sentences. Played back-to-back with no gap, the agent sounds mechanical. Real conversations have rhythm: pauses between thoughts, variation in pacing. So we insert small breaks with varied timing between sentences, which keeps the agent from sliding into a flat robotic cadence.
Text also has to become speakable before it reaches the voice model. Healthcare workflows are full of abbreviations, dates, IDs, payer names, and procedure codes that look fine on screen but sound wrong out loud. "DOB" needs to become "date of birth." A phone number reads digit by digit, not as one large number. An NPI number can't be pronounced like a word.
We use ElevenLabs because voice quality sets the agent's personality, and there are limits to how much you can reshape a voice after the fact. A voice that naturally sounds energetic won't reliably become calm just because you ask it to. The base voice matters more than the settings on top of it.
The reps on the other end of these calls take hundreds a day. A clear, well-paced voice is what keeps the conversation moving and gets us better information back.
The Work Ahead
Somewhere right now, a parent is waiting for their child's therapy to be approved. A clinic is on hold with an insurance company, again. A nurse is reading a member ID into a phone tree for the third time this morning. Healthcare runs on these phone calls, and the people making them are burning out.
We're building the systems that take those calls off their plate, and we're building them to scale. One agent that works is a demo. Dozens of agents handling thousands of calls a day across every major payer, every specialty, every workflow that today requires a human on hold: that's the platform. It means real-time audio pipelines that hold up on a live phone call, agents that can't afford to be wrong on a member ID, and the eval, A/B, and deployment infrastructure to launch the next agent faster than the last. A fluent wrong answer can delay a patient's care, so every layer has to earn its place.
Every call we automate is an hour given back to a clinic, a day saved off a prior auth, a patient who gets care sooner. We're early, the surface area is enormous, and the work compounds. The system we build this year decides how fast we can move next year. If you want to work on infrastructure that takes phone calls off healthcare's critical path, come build it with us.
Join our team
Found this interesting? We're building the future of healthcare technology and looking for talented engineers to join us.
View open positions