Autonomous Browser Agents in the Enterprise
Prior authorization exists to control costs, but the process often delays treatment. Patients wait days for approvals that require clinical staff to navigate insurance portals, enter data, and chase down responses across dozens of payers. We built autonomous browser agents to compress that timeline. Every day, they submit nearly twenty percent of our prior authorization volume. Over the past year, we've scaled that volume 7x - and the infrastructure we built to get there has since powered products we hadn't originally planned for. What started as a demo is now a critical part of how we clear patients for care.
The agents handle the full workflow on insurance portals: logging in with 2FA, navigating complex legacy UIs, entering clinical data, and recording approvals directly into our system. Work that used to take trained clinical staff hours to complete, repeated across Blue Cross, Aetna, United, and dozens of other portals, each with its own quirks and credentials.
We evaluated several vendors for sandboxed VMs and remote browsers before landing on a self-hosted deployment of Kasm Workspaces. Owning the infrastructure is what lets us meet the security bar required for agents handling sensitive patient data: full control over data isolation, no unauthorized outflows, and complete auditability.
Our browser infrastructure also enables seamless handoffs between agents and humans for when the agent encounters something it cannot solve with confidence. There is no RL gym for the Blue Cross Blue Shield of Tennessee portal, and it doesn't make sense to build them for thousands of portals. You can't submit fake prior authorizations to test your changes. So we built tooling for real-time supervised experiments, carefully rolling out changes in production and observing the results.
This post walks through how we built our browser agents: secure browser session management, durable task orchestration, context management across long-running workflows, and scheduling systems that scale to thousands of concurrent agents.
Prior Authorization Portals
We started the way most healthcare companies do: employees logging into portals from their own machines, managing credentials individually. That doesn't scale when you're handling tens of thousands of prior authorizations. We needed browser sessions that were isolated, auditable, and provider-scoped.
We landed on a self-hosted deployment of Kasm Workspaces because it's container-based, fully API-driven, and gave us everything we needed: session isolation with no state leakage, network-level URL whitelisting, full video recording of every session, file upload/download interception, and programmatic provisioning. We built a session management layer on top that handles the lifecycle of every browser interaction:
User/Agent requests session → Session queued → Container provisioned → Policies injected → Session active → Work completed → Files synced → Session destroyed → Recording archived
Every session is tied to a specific healthcare provider via our Row-Level Security system.
For example: a session created for Provider A cannot access data belonging to Provider B, enforced at the database level. When a session starts, Chrome policies lock the browser to the target portal's domain. When it ends, all artifacts sync to S3 with full metadata. If someone asks "what happened in that submission three months ago," we can show them the task, the file uploads, the downloads, and a frame-by-frame video.
When we started experimenting with browser automation, isolation and auditability were already solved. The Chrome DevTools Protocol (CDP) access we'd spec'd as a "nice to have" let us connect Playwright to running Kasm sessions while maintaining every security guarantee. The URL whitelisting that kept employees on-task became the guardrails that kept agents from navigating to domains they should never access. The session recordings built for compliance became the debugging tool that let us watch exactly what an agent did when it failed.
Task Orchestration
Before an agent can fill out a portal form, you need to extract clinical data from messy PDFs, validate that the extractions are accurate, identify where in the source documents the data came from, and prepare everything the agent will need to complete the submission. This is dozens of LLM calls, document processing steps, and validation checks, all of which need to be completed reliably before the agent touches a browser.
We needed orchestration backed by Postgres: queryable, recoverable after any crash, and not another stateful system to operate. We already used Dramatiq for task execution, so we built the orchestration layer on top of it. We call it Pipelines: a framework that models workflows as composable trees of steps. Every step, every result, every failure is persisted to disk and queryable with SQL. The interface borrows directly from Celery's primitives: steps compose into chains and groups, which themselves compose recursively. Steps can branch conditionally based on upstream results, so a pipeline can route differently depending on what the extraction step finds in the clinical documents.
A prior auth form might need the patient's diagnosis, the requested procedure, treatment goals, and supporting clinical notes. Each of these extractions is independent, so we can run them simultaneously. But the browser agent submission depends on all of them completing. Pipelines let us express this naturally. Here's the simplified structure:
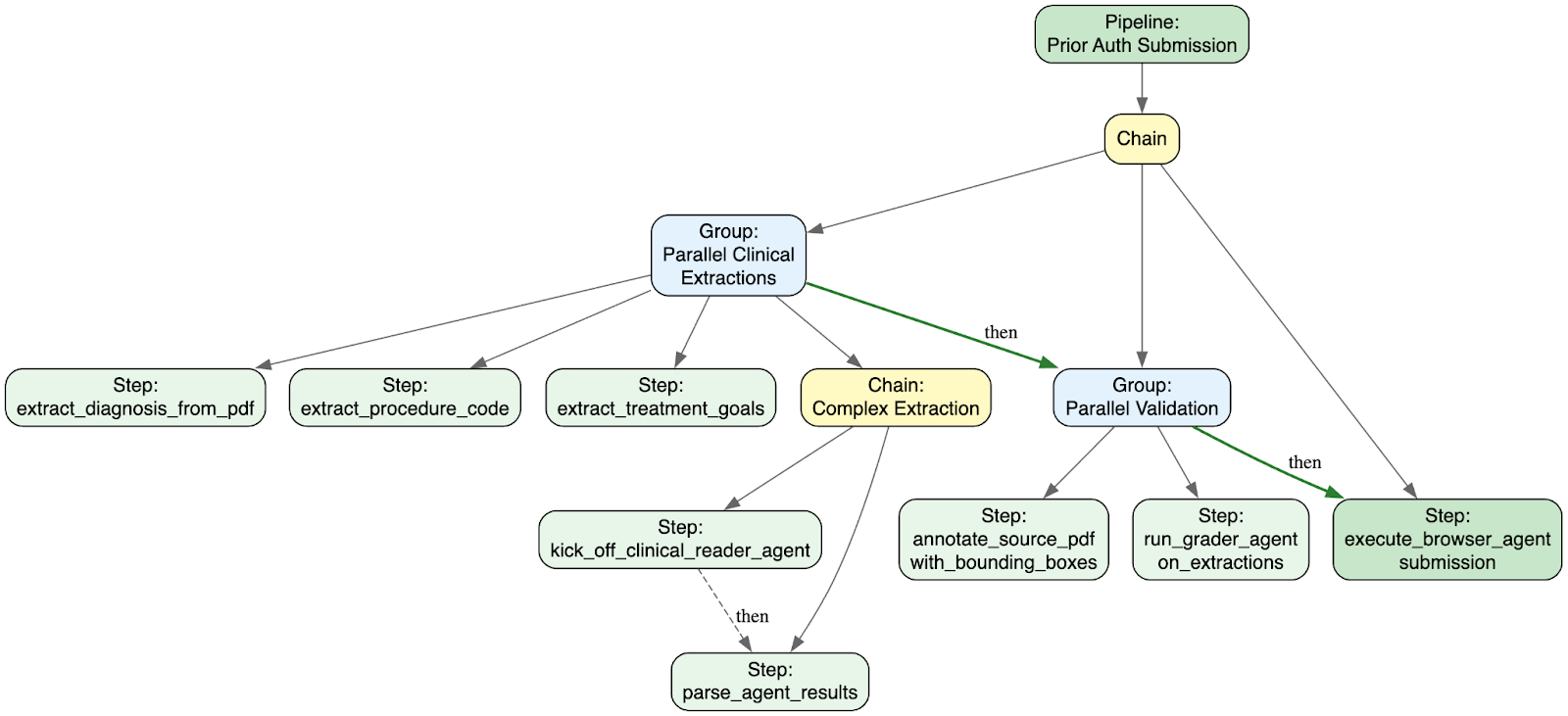
The actual pipelines are more complex. A single prior auth submission might fan out into dozens of parallel extraction steps, each one processing a different clinical field from the source documents. Here's what that looks like in production:
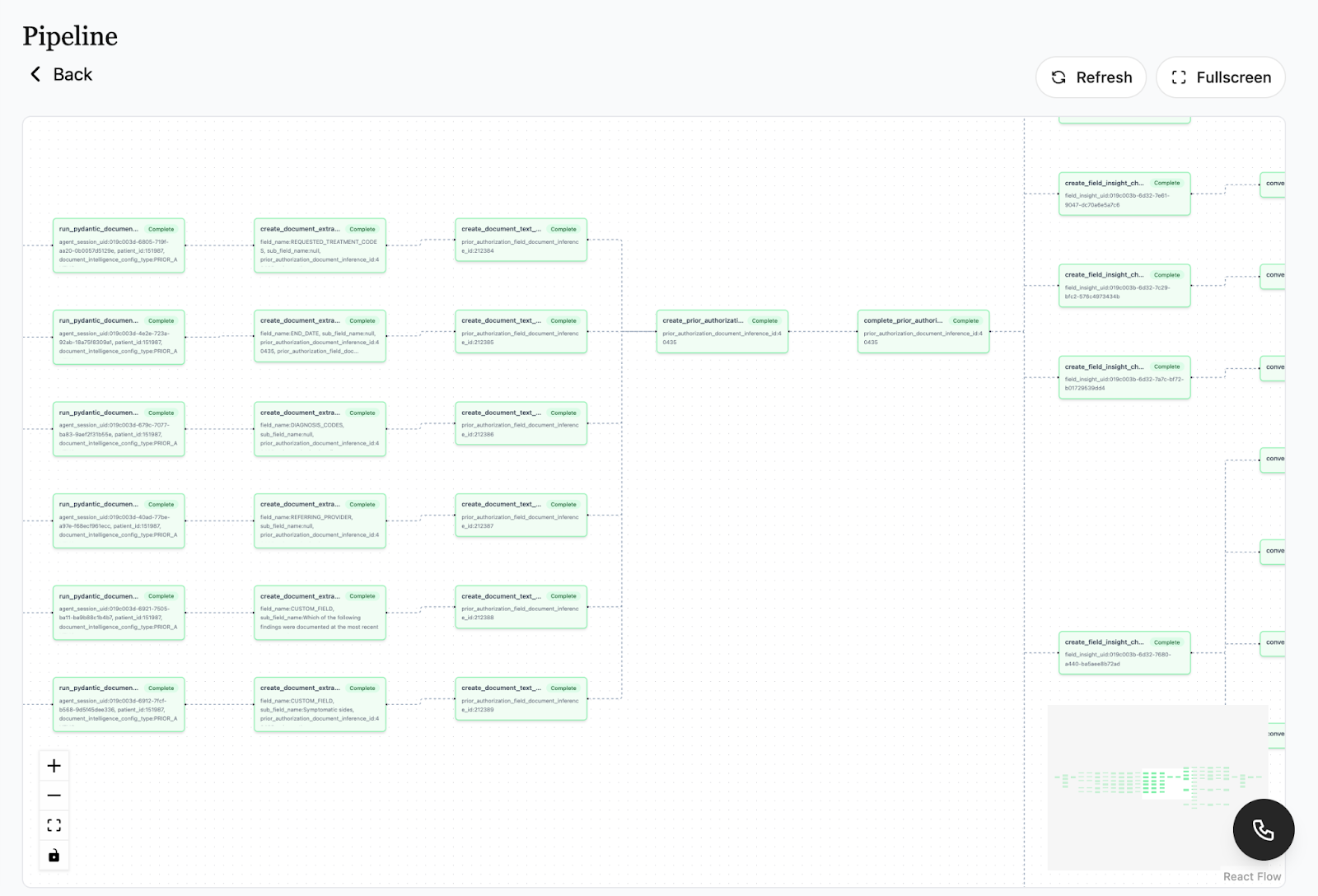
When something fails, you're not digging through logs. You're clicking on the red node. This visibility is what gave us the confidence to start putting real patient submissions through the system.
High Trust Agents
Insurance portals assume human intuition: that you'll guess "Auth Type" means "Service Category," or know from experience that clicking "Save" before "Submit" is required or the form silently discards your data. Agents don't have that intuition, and every portal is its own snowflake. Anthem's workflow looks nothing like Cigna's. United has three different portals depending on the plan type. Some portals time out after ten minutes. Others have CAPTCHAs that appear randomly on the third page. We learned that reliability comes from making agents' environments more constrained and their feedback loops tighter.
The Authentication Gauntlet
Before an agent can do anything useful, it needs to log in:
- Username and password (the easy case)
- TOTP codes from an authenticator app
- Email OTP codes sent to a shared inbox
- SMS codes sent to a phone number we control
- Security questions ("What was your first pet's name?")
- CAPTCHAs that appear inconsistently
We built tools for each of these. The agent requests credentials for a portal and gets back the username and password, pulled from encrypted storage and scoped to the provider. Our ZDR policies with model providers ensured that credential leakage would not occur.
TOTP was straightforward: we store the secret, generate codes on demand, and built a tool that handles the common pattern of "fill the code and click verify" as a single atomic action. The agent doesn't fumble with timing windows.
Email OTP was harder. Multiple agents might be logging into the same portal simultaneously, all triggering OTP emails to the same shared inbox. We built an email OTP tool with distributed locks that serialize access: one agent triggers the email, waits for it to arrive, extracts the code, and completes login before the next agent can start. The lock times out after five minutes to prevent deadlocks if something fails mid-flow.
A prior authorization submission can take fifty or more steps. The agent logs in, searches for the patient, opens the correct form, fills dozens of fields across multiple pages, uploads documents, reviews the submission, and confirms.
Rather than asking agents to figure out each portal from scratch, we maintain instructions tailored to each one: "On this portal, you must click 'Attach' after uploading files or they won't be associated with the submission." These playbooks can be maintained by our non-technical team members as they are all in English instead of code. When a portal changes its UI or we discover a new edge case, ops updates the playbook and every subsequent agent picks up the change without a code deploy.
Context management matters more than we initially expected. Agents that can see their entire conversation history eventually drown in it - they start relitigating decisions from twenty steps ago instead of focusing on what's in front of them. We limit how far back an agent can see, keeping recent screenshots and actions while older context gets summarized or dropped entirely.
Hard stops prevent a whole class of disasters. Once an agent believes it has completed a submission, execution halts immediately. It doesn't get another turn to second-guess itself or accidentally click "Cancel." We also cap total turns - if an agent hasn't succeeded in fifty steps, something is wrong and a human needs to look at it.
And we built explicit escape hatches. An agent that says "I'm stuck and need help" is far more valuable than one that confidently submits garbage, so we invested heavily in training agents to bail out gracefully rather than hallucinate their way through problems.
Validating Success
Every session gets scored on "smoothness" - how directly did the agent reach its goal versus how much did it backtrack, retry, and stumble? A smooth session means the agent knew what to do and did it. A rough session means it got there eventually, but barely. Low smoothness scores trigger human review even if the agent claims everything went fine.
We also detect failure patterns automatically: agents stuck in retry loops, agents claiming to see UI elements that aren't in the screenshots, agents whose stated reasoning contradicts their actual actions. When these patterns show up, the session gets flagged.
For submissions that produce submission confirmations and/or approval letters, we validate that the downloaded document actually contains what we expect - the right patient, the right procedure, a reference number. If anything's missing or doesn't match, a human reviews before we consider the submission complete.
AI Ops: Humans in the Loop
We created a new function, AI Ops, to own agent deployments. They're technically savvy operators who understand insurance workflows deeply and can translate that domain knowledge into agent configurations, playbooks, and live experiments.
When a portal changes its UI, AI Ops updates the playbook. When we onboard a new payor, AI Ops writes the initial instructions based on manual submissions, then iterates as the agent encounters edge cases. When success rates drop on a portal that used to work fine, AI Ops investigates and patches the configuration. Engineers own the infrastructure; AI Ops owns the domain knowledge.
Since these portals have no staging environments, AI Ops runs live experiments, routing a percentage of submissions through different model configurations and measuring success rates in production.
Deployed At Scale
Scaling from tens of agents per day to thousands exposed problems we hadn't anticipated.
Durable Agents
Our first agent implementation used the OpenAI Agents SDK. We'd call into the SDK, it would handle the loop of inference and tool execution, and our session store would persist messages to Postgres along the way. Persistence happened at turn boundaries: after the model responded and after a tool designated as "terminal" stopped executing. If a worker crashed mid-run, that run's work was lost.
A crashed turn meant one submission retried from a slightly earlier state, but at scale, the math changed. Worker deployments happened multiple times per day. Some tool executions - file uploads, PDF downloads, complex browser interactions - could take thirty seconds or more. A crash during any of these meant losing real work, and at high volume, small loss rates compounded into real pain.
Durability on top of the Agents SDK exists via integrations - it has built-in support for DBOS or Temporal-backed agents. However, since we use an in-house system, we rebuilt the agent runtime on top of our own. Instead of one long-running process handling the full agent loop, each inference call became its own pipeline step. Each tool execution became its own pipeline step. After inference completes, we dynamically spawn the tool steps, then the next inference step. Every step persists its result before completing.
Instead of engineers building Pipelines, the agent began constructing its own.
If a worker dies during inference, the pipeline retries just that inference step. If a worker dies during a tool call, it retries just that tool call. The pipeline structure lives in Postgres, so any worker can pick up exactly where the previous one stopped. And because each step is its own queued task, deploys don't cause cascading retries - the pipeline system just routes the next step to an available worker without backoff penalties.
The tradeoff is complexity. Dynamically spawning follow-up steps based on what tools the model decides to call is more intricate than a simple while loop. But crashes stopped meaning lost work, and we got visibility into exactly what's happening at each stage of every session.
Credential Pooling
Our original credential model was simple: one credential per portal, per provider, per payor. A single set of login details for each combination. This worked when agents ran one at a time, but sometimes broke down when we needed multiple agents hitting the same portal simultaneously.
The occasional portal aggressively terminates concurrent sessions on the same credential. Others rate-limit login attempts. When five agents tried to log into the same portal at once, four of them would fail - either kicked out mid-session or blocked at the login page.
Instead of one credential per scope, we maintain multiple credentials, and agents lease them for the duration of their session. When an agent starts, it claims an available credential from the pool. When it finishes - successfully or not - the credential goes back into rotation. For portals that had limited our credential-based session throughput, we enabled this feature. If every credential in a pool was in use, the agent queued and waited, which meant we now needed a smarter way to decide what ran when.
Scheduling Under Contention
Browser sessions aren't cheap. Each one is a container with dedicated CPU and memory running a full Chromium instance. When demand exceeds capacity, first-come-first-served doesn't work: a bulk job kicking off hundreds of follow-up checks would starve out time-sensitive submissions, and a human operator needing a browser would wait behind a queue of agents. We built priority tiers (humans first, deadline-sensitive submissions next, bulk automation last) with time-based priority boosting so low-priority work doesn't starve. This became the coordination point that let us enable bulk kickoffs at a client level without overwhelming our infrastructure or flagging suspicious activity on the portals.
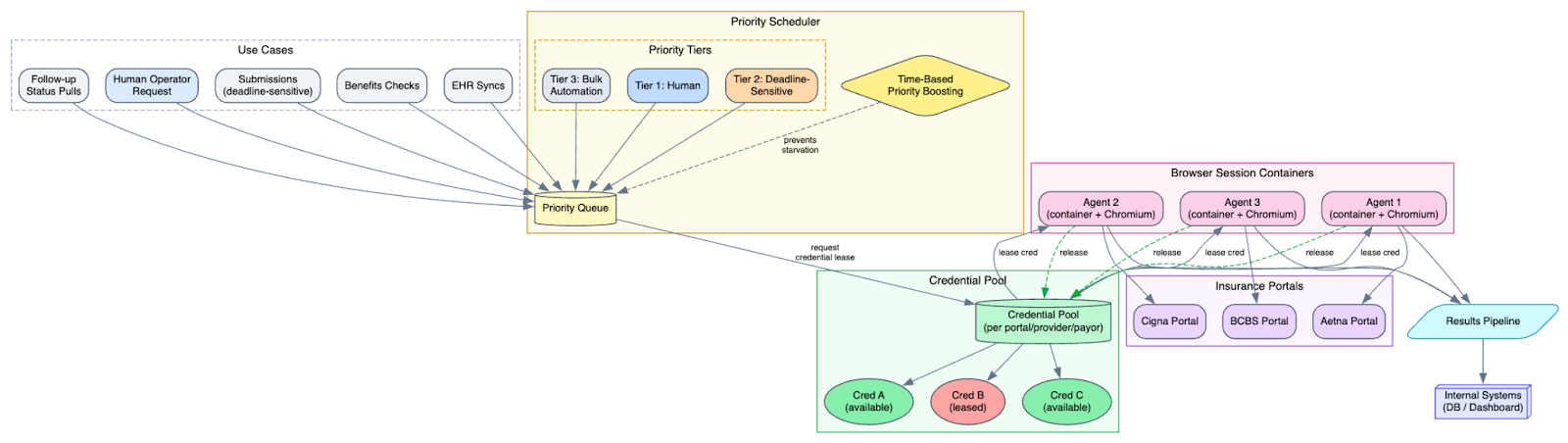
Each new use case (benefits checks, EHR syncs, follow-up status pulls) had its own quirks but fit the same pattern: secure browser session, agent with tools and instructions, pipeline-backed execution, results flowing back to our systems. The architecture we built for prior auth turned out to be a general-purpose system for putting agents on legacy web infrastructure. We didn't plan for that, but it's not an accident either. The constraints we imposed early (session isolation, full auditability, provider-scoped credentials) were the same properties that made the system safe to extend.
If there's a throughline to what we've learned, it's that reliability comes from constraint more than raw capability. Agents get better when you shorten their context windows, hard-stop their execution, give them explicit permission to bail out, and pair them with humans who understand the domain. The Silicon Valley dogma says to give agents more autonomy. In practice, building a tight harness is what lets us deploy them on real patient submissions and deliver real outcomes.
Human infrastructure matters as much as technical infrastructure. AI Ops isn't a stopgap until the agents get smarter. It's the function that translates a changing world's nuances into agents faster than any engineering team could ship code. The agents handle volume. The humans handle novelty. We build both to be reliable, because behind every submission is a patient waiting to start treatment.
Join our team
Found this interesting? We're building the future of healthcare technology and looking for talented engineers to join us.
View open positions